

A simple guide to JavaScript concurrency in Node.js and a few traps that come with it



Photo by Rahul Mishra on Unsplash
Why is it that despite its single-threaded design, Node.js is still capable of handling concurrency and multiple I/O operations at the same time? Well, it’s all thanks to its asynchronous nature. I could end it right here and call it a day. Or I could go on to explain this asynchronous nature in full, complete with practical examples, related concepts and many other things. And that’s exactly what I am about to do. Welcome to my deep dive into concurrency in Node.js!
I bet that you are familiar with JavaScript concurrency in Node.js. Also, most probably you have already heard that Node excels at handling multiple asynchronous I/O operations.
But have you ever wondered what it really means? There are lots of potential points of contention. How is it exactly done in Node.js? Isn’t it single-threaded? What about operations other than I/O? Is there any way you can handle them without making your app unresponsive?
What you’ll learn
In the article, I’m hoping to clarify how Node deals with asynchronicity under the hood. I’ll try to explain what are the potential traps that you should be aware of. Also, I’ll focus on how Node’s new features might help you push your applications even further than ever before. Full list of topics include:
the theory behind concurrency in Node.js (sequence vs concurrency vs parallel),
implications of using a single thread in Node.js,
comparison of blocking and non-block I/O operations in Node.js,
non I/O operations,
the JavaScript event loop,
the cluster mode,
worker threads.
Sounds good? Let’s go for it.
Let’s start with the concurrency in Node.js theory
Before I’ll start talking about Node.js, let’s quickly distinguish two terms that might be a little confusing. These are concurrent and parallel concurrency in Node.js. Let’s imagine that you have two operations: A and B. If you weren’t dealing with any concurrency at all, you would start with the operation A. Once it’s completed, you would start the operation B, so they would simply run sequentially. Such execution will look like the one on the diagram below.
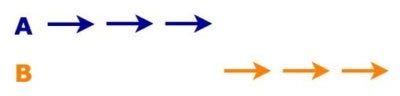
Operations running sequentially
Once operation A is completed, you start the operation B — they are run sequentially.
If you want to handle these operations concurrently, the execution will look like this.
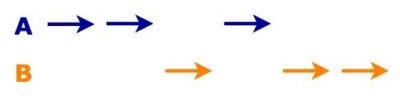
Operations running concurrently
The alternative solution is to handle the operations concurrently.
These operations don’t run sequentially, but neither are they executed simultaneously. Instead, the process “jumps” or switches context between them.
You can also execute these operations in parallel. Then, they run simultaneously on two separate CPUs. In theory, they can be started and finished at the same time.
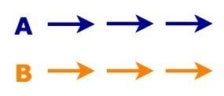
Operations running in parallel
The third option is to run the operations in parallel.
One thread to rule them all
Node took a slightly different approach to handling multiple concurrent requests at the same time if you compare it to some other popular servers like Apache. Spawning a new thread for each request is expensive. Also, threads are doing nothing when awaiting other operations’ result (i.e.: database read).
That’s why Node is using one thread instead.
Such an approach has numerous advantages. No overhead comes with creating new threads. Also, your code is much easier to reason about, as you don’t have to worry about what will happen if two threads access the same variable. It’s because that simply cannot happen. There are some drawbacks as well. Node isn’t the best choice for applications that mostly deal with CPU intensive computing. On the other hand, it excels at handling multiple I/O requests. So, let’s focus on this part for a bit.
I/O operations and Node
Firstly, I should answer the question: what do you mean by I/O operations? These are operations that communicate with stuff from the outside of your application. It means HTTP requests, disk reads and writes or database operations, just to name a few. I/O in Node comes in two “flavors”: blocking and non-blocking. It’s quite important to distinguish these two. “Blocking” in “blocking I/O operations” is quite self-descriptive.
It means that next operations are blocked and that they have to wait as long as the currently running operation is taking.
Let’s take a look at the example.
fs.readFileSync(filePath1)fs.readFileSync(filePath2)console.log(‘Logging after both reads are finished’)
view rawblocking-io.js hosted with ❤ by GitHub
In the example, you trigger the first read and then, only after it’s finished you start the second one. console.log will happen once both reads are completed.
The non-blocking model works in a pretty different way. Let’s take a look at an example once again.
fs.readFile(filePath1, (err, content) => { if (err) // handle error // otherwise do something with the content}) fs.readFile(filePath2, (err, content) => { /* same story */ }) console.log(‘Will happen before any of the reads is finished’)
view rawnon-blocking-io.js hosted with ❤ by GitHub
Here, the first read operation is triggered, but the code is not stopped. You also trigger the second read and right after that — console.log writes to the console. What about the results of the two read operations? Well, they will be handled asynchronously. It means that you’ll receive their results in the future, and you have no guarantee which operation finishes first.
Which one should you prefer?
Instead of giving the answer, let’s conduct an experiment. Let’s use Express and create a very simple HTTP server with two endpoints. First one reads some data from the file asynchronously (non-blocking I/O) and the other reads them synchronously (blocking I/O). Let’s assume that you wrapped standard readFile and readFileSync methods with some magic, so they take an extra 75 ms to finish. It will look like this.
const express = require(‘express’) const app = express()const port = 3055 app.get(‘/async’, async (req, res) => { const user = await readUserAsync() res.send(user)}) app.get(‘/sync’, (req, res) => { const user = readUserSync() res.send(user)}) app.listen(port, () => console.log(`Example app listening on port ${port}!`))
view rawexpress-endpoints.js hosted with ❤ by GitHub
If you want to compare the performance of these two endpoints you could use one of the available benchmarking tools (let’s say — you’re interested in how many requests you can handle within 5 seconds and up to 10 requests are concurrent). I chose Apache Benchmark. It’s been there for quite some time, but it’s built into macOS. It’s doing its job just fine. Let’s run the following benchmark, first for the synchronous/blocking endpoint.
ab -c 10 -t 5 “http://localhost:3055/sync"
view rawbenchmark.sh hosted with ❤ by GitHub
The benchmarking tool will give you plenty of interesting statistics, but let’s focus on how many requests you can handle per second.
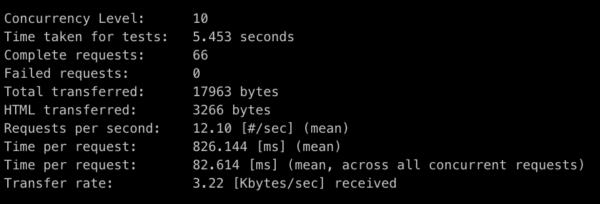
Requests per second
As you can see — you’re capable of handling about 12.1 requests per second, which makes sense. You’re only able to handle one request at the time, it takes about 80ms (75 of your “extra” read time, plus a few milliseconds to read the file and handle the request). So, you can easily calculate how many requests per seconds you can handle. It’s 1000 ms (1 second) / 80 ms = 12.5 request per second, so you’re quite close.
Now, let’s take a look at the benchmark for the asynchronous/non-blocking endpoint below.
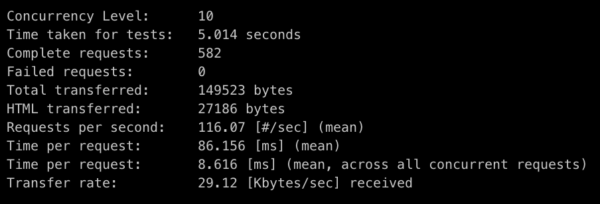
The asynchronous/non-blocking endpoint benchmark
You can see that the result is much better in this example. You can handle over nine times more results per second than in the blocking version (and the difference would be more significant for longer read times). So it should be clear which version you should favor.
Highlight: Always favor non-blocking I/O over blocking I/O.
But… how?
You can see that Node works quite well when it comes to handling I/O operations asynchronously. It might be a little surprising when one knows that it works with just one thread. Doesn’t one thread equals to one operation at the time? Well… yes and no.
To be less vague, you can indeed handle only one JavaScript operation at the time, however, you can take advantage of the fact that modern operating systems’ kernels are multi-threaded. So you can delegate I/O operations to them.
That brings us another question. When such operations are completed, how does Node know that it’s time to handle them? You can imagine that it can’t happen anytime, otherwise — your applications would be a nightmare to work with. Imagine that you’re doing an operation and suddenly in the middle of it — a callback is triggered because the disk operation has just finished. I think you’ll agree that it’s not the way to go. So, let’s introduce someone that’ll help Node manage all this mess.
What is the JavaScript Event Loop?
Let’s briefly explain what Event Loop is and how it works. Previously, I’ve mentioned that you need some kind of “manager” to be able to handle async programming or asynchronous operations. That’s precisely what Event Loop does. Let’s take a look at an example of an async operation.
asyncOperation(param1, param2, function(error, result) { /* … */ })
view rawasync-operation.js hosted with ❤ by GitHub
The interesting part of this asynchronous code here is a function that you pass as the last argument. It’s a callback function that will be called once your operation is finished, but not immediately. We agreed that such things shouldn’t happen anytime and Event Loop will make sure of that. Once your operation is finished, instead of calling the callback right away, it will place it into a special event queue. Once it’s possible to handle it safely, your callbacks will be pushed to the stack and then executed one by one.
You should be careful here, even if your I/O operation was asynchronous, the callback will be handled on the main thread, assuming it’s a JS operation. So, if you’re doing something time consuming, you’ll be blocking the Event Loop.
This is, of course, a great simplification of how Event Loop works. If you’d like to learn more about it — you can check this great Event Loop section from a Rising Stack article — or take a look at this video introduction below.
What about non I/O operations?
Okay, so I covered a piece of information about a great deal with the use of blocking and non-blocking I/O. You saw that Node deals quite well with the latter and now you know how to do it. Event Loop for the win! What about the stuff that doesn’t deal with I/O, but may process some heavy computing for you? For example — sorting a huge list. Unfortunately, this is where Node single-threaded environment won’t shine that bright. Let’s jump back into our example with Express API. You saw that Node deals quite well with handling requests to your asynchronous endpoint. What would happen if the same API exposed a new endpoint which did some heavy computing that takes a few seconds?
app.get(‘/timeConsumingEndpoint’, (req, res) => { doSomeHeavyComputing() res.sendStatus(200)})
view rawtime-consuming-endpoints.js hosted with ❤ by GitHub
Now, let’s imagine a scenario where this endpoint is being used by some batch job to process some data. In such a scenario, you’re not even doing any concurrent requests. Instead, you’re making sure that your server is constantly spinning and doing some job for you. What would happen if you’d run some benchmarks on your old asynchronous endpoint (let’s name it /async), while your CPU intensive task is constantly running? Let’s see.
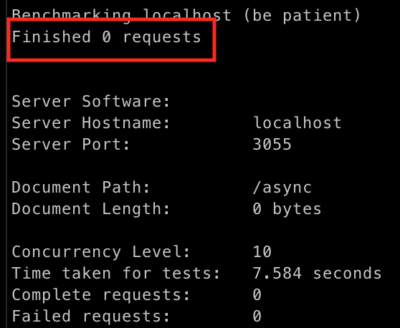
API becomes unresponsive
Yup, you’re right. Your API is pretty much unresponsive at the moment. If you’re unaware of the limits of Node’s single thread, then unfortunately, you can achieve such unresponsiveness pretty easily. Is there anything you can do to somehow fix this case? One idea that comes to mind is to scale your app. But you don’t need help from the DevOps team to do that. Fortunately, Node has some built-in mechanisms that allow you to achieve it.
Cluster mode
The official documentation explains it quite nice, so I won’t be reinventing the wheel and will simply quote it here.
A single instance of Node.js runs in a single thread. To take advantage of multi-core systems, the user will sometimes want to launch a cluster of Node.js processes to handle the load.
So, what Cluster Mode gives you is a very basic load balancer. It will distribute the load in the round-robin approach between the nodes. Sounds pretty nice, doesn’t it? Nowadays, we have fancy CPUs with multiple cores, so it makes sense to take advantage of them. Especially if your application became so hopelessly unresponsive.
Let’s take a look at how this may look.
if (cluster.isMaster) { console.log(`Master ${process.pid} is running`) for (let i = 0; i < numCPUs; i++) { cluster.fork() } cluster.on(‘exit’, (worker, code, signal) => { console.log(`worker ${worker.process.pid} died`) })} else { const express = require(‘express’) const app = express() // define our endpoints here app.listen(port) console.log(`Process ${process.pid} started`)}
view rawapi-with-cluster.js hosted with ❤ by GitHub
Nothing too complicated, right? The fact that you don’t have to bother the DevOps team makes it even better! If you’ll run your API, you can see that you indeed spawned some processes.
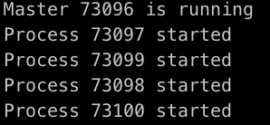
New processes
Now, let’s see if this fixed the problem. Your long-running job is opened in the background, your Super Important Algorithm is still doing its job, so let’s run the benchmark again.
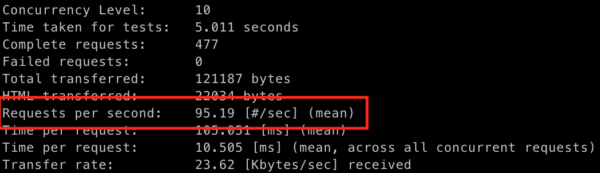
A new benchmark
Looks good, doesn’t it? But you will probably agree that your CPU intensive endpoint isn’t that busy right now. What if someone decided to speed some things up and run, let’s say, five concurrent jobs (or just any number of jobs that exceeds the number of CPUs on the server) that are consuming this endpoint?
You will see the same thing as you did before introducing Cluster Mode. No responses whatsoever. And what would happen if you expose this endpoint to the public, for the whole world to use it? You can see that as nice and easy to use Cluster Mode is, it doesn’t really solve the problem if you’re able to make each process unresponsive so quickly.
Are you doomed then? Well, luckily you are not. Some time ago, one of the Node releases gave us all a nice surprise, namely…
Worker Threads!
Worker threads are still an experimental feature in Node.js-based web development, meaning using them on production environment probably isn’t the best idea. But there’s a chance this will change soon. Worker Threads allow you to execute code in JavaScript in the parallel, making working with multiple tasks or multiple requests easier. It sounds exactly like something that you can use in the aforementioned scenario. Let’s take a quick look at how you could introduce Worker Threads to your API. The first thing you have to do is to create a new file. I named it heavy-computing-with-threads.js.
const { Worker, isMainThread, parentPort } = require(‘worker_threads’) if (isMainThread) { module.exports = async function timeConsumingOperationOnThreads(raw) { return new Promise((resolve, reject) => { const worker = new Worker(__filename, { workerData: raw }) worker.on(‘message’, resolve) worker.on(‘error’, reject) worker.on(‘exit’, (code) => { if (code !== 0) { reject(new Error(`Worker stopped with exit code ${code}`)) } }) }) }} else { const result = doSomeHeavyComputing() parentPort.postMessage({ result})}
view rawheavy-computing-with-threads.js hosted with ❤ by GitHub
Not too complicated, right? First, you check whether you are on the main thread. If you are, then you spin a new worker thread and handle some basic communication with it. After that, you wrap it all up with a Promise which is quite a useful pattern in Node. It makes working with a callback or event-based code much easier. If you are not on the main thread that means you’re on one of the spawned threads, and that’s where you can run your long-running operation.
Now, you simply have to modify your Express API so it uses this version of the CPU intensive algorithm.
const timeConsumingOperationWithThreads = require(‘./heavy-computing-with-threads’)/* … */ app.get(‘/timeConsumingEndpoint’, async (req, res) => { const result = await timeConsumingOperationWithThreads() res.send(result)})
view rawapi-with-threads.js hosted with ❤ by GitHub
If you run benchmarks again (even with the version which was making concurrent requests to the long-running endpoint) everything should be fine. Your other endpoints are responsive again!
Interested in developing microservices? 🤔 Make sure to check out our State of Microservices 2020 report — based on opinions of 650+ microservice experts!
Few more things to remember
Besides being useful when using experimental Worker Threads, you should also keep in mind that they are not necessarily useful for handling I/O operations. What’s already been built into Node before Worker Threads will work much better. And one last thing — if you take a look at your API which is using threads, you’ll see that you’re spinning a new thread for each request. That won’t be too efficient in the long run. What you should do instead is to have a pool of threads and re-use these. Otherwise, the cost of creating new threads will overcome their benefits.
Only a single thread — as for concurrency in Node.js…
I hope I briefly walked you through some of the traps that you can encounter if you’re not aware of Node single-threaded nature. Here a couple of things to keep in mind:
Remember to favor non-blocking I/O over blocking I/O.
You should keep in mind that each JavaScript operation will block the Event Loop and that long-running operations are especially dangerous in that matter.
Be aware of the built-in scaling that Cluster Mode gives you, but also be aware that it won’t necessarily solve the problems that come with CPU intensive operations in Node. For these, there’s a much better solution that came quite recently — Worker Threads. Just bear in mind that they’re still experimental, but follow the newest Node releases, as this may change anytime!
As you can see, when it comes to concurrency in Node.js, there are a lot of interesting developments and workarounds, but there is still much to do before everything works as well as we’d like to. You still can’t do it without having to worry about the CPU, but perhaps it’s for the better!
I am currently building a newsletter to share informative articles and news, covering ai, startups 🚀, tech 📱, and programming 💻! my progress in becoming Software Developer with little experience, and how you can learn from my experience.
Please subscribe via this link.
Also published here.